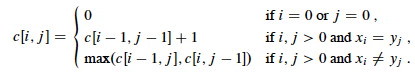 Dynamic programming avoids the redundant computations by storing the results in a table. We use
c[i,j] for the length of the LCS of prefixes Xi and
Yj (hence it must start at 0). (b is part of the third step and is
explained next section.)
Dynamic programming avoids the redundant computations by storing the results in a table. We use
c[i,j] for the length of the LCS of prefixes Xi and
Yj (hence it must start at 0). (b is part of the third step and is
explained next section.)A subsequence of sequence S leaves out zero or more elements but preserves order.
Z is a common subsequence of X and Y if Z is a subsequence
of both X and Y.
Z is a longest common subsequence if it is a
subsequence of maximal length.
Given two sequences X = ⟨ x1, ..., xm ⟩ and Y = ⟨ y1, ..., yn ⟩, find a subsequence common to both whose length is longest. Solutions to this problem have applications to DNA analysis in bioinformatics. The analysis of optimal substructure is elegant.
For every subsequence of X = ⟨ x1, ..., xm ⟩, check whether it is a subsequence of Y = ⟨ y1, ..., yn ⟩, and record it if it is longer than the longest previously found.
This involves a lot of redundant work.
Many problems to which dynamic programming applies have exponential brute force solutions that can be improved on by exploiting redundancy in subproblem solutions.
The first step is to characterize the structure of an optimal solution, hopefully to show it exhibits optiomal stubstructure.
Often when solving a problem we start with what is known and then figure out how to contruct a solution. The optimal substructure analysis takes the reverse strategy: assume you have found an optional solution (Z below) and figure out what you must have done to get it!
Notation:
Theorem: Let Z = ⟨ z1, ..., zk ⟩ be any LCS of X = ⟨ x1, ..., xm ⟩ and Y = ⟨ y1, ..., yn ⟩. Then
Sketch of proofs:
(1) can be proven by contradiction: if the last characters of X and Y are not included in Z, then a longer LCS can be constructed by adding this character to Z, a contradiction.
(2) and (3) have symmetric proofs: Suppose there exists a subsequence W of Xm-1 and Y (or of X and Yn-1) with length > k. Then W is a common subsequence of X and Y, contradicting Z being an LCS.
Therefore, an LCS of two sequences contains as prefix an LCS of prefixes of the sequences. We can now use this fact construct a recursive formula for the value of an LCS.
Let c[i, j] be the length of the LCS of prefixes Xi and Yj. The above recursive substructure leads to the definition of c:
We want to find c[m, n].
A recursive algorithm based on this formulation would have lots of repeated subproblems, for example, on strings of length 4 and 3:
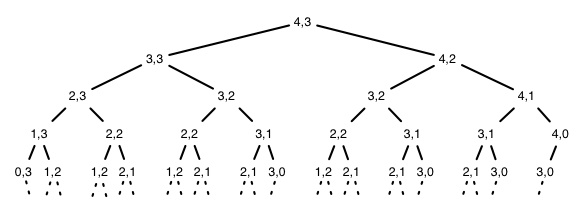
Dynamic programming avoids the redundant computations by storing the results in a table. We use
c[i,j] for the length of the LCS of prefixes Xi and
Yj (hence it must start at 0). (b is part of the third step and is
explained next section.)
Try to find the correspondence betweeen the code below and the recursive definition shown in the box above.

This is a bottom-up solution: Indices i and j increase through the loops, and references to c always involve either i-1 or j-1, so the needed subproblems have already been computed.
It is clearly Θ(mn); much better than Θ(n2m)!
In the process of computing the value of the optimal solution we can also record the choices that led to this solution. Step 4 is to add this latter record of choices and a way of recovering the optimal solution at the end.
Table b[i, j] is updated above to remember whether each entry is
We reconstruct the path by calling Print-LCS(b, X, n, m) and following the arrows, printing out characters of X that correspond to the diagonal arrows (a Θ(n + m) traversal from the lower right of the matrix to the origin):

What do "spanking" and "amputation" have in common?

Another application of Dynamic Programming is covered in the Cormen et al. textbook (Section 15.4). I briefly describe the problem here, but you are responsible for reading the details of the solution in the book. Many more applications are listed in the problems at the end of the Chapter 15.
We saw in Topic 8 that an unfortunate order of insertions of keys into a binary search tree (BST) can result in poor performance (e.g., linear in n). If we know all the keys in advance and also the probability that they will be searched, we can optimize the construction of the BST to minimize search time in the aggregate over a series of queries. An example application is when we want to construct a dictionary from a set of terms that are known in advance along with their frequency in the language. The reader need only try problem 15.5-2 from the Cormen et al. text (manual simulation of the algorithm) to appreciate why we want to leave this tedium to computers!
To use dynamic programming, we must show that any optimal solution involves making a choice that leaves one or more subproblems to solve, and the solutions to the subproblems used within the optimal solution must themselves be optimal.
We may not know what that first choice is. Consequently:
How many subproblems are used in an optimal solution may vary:
How many choices in determining which subproblem(s) to use may vary:
Informally, running time depends on (# of subproblems overall) x (# of choices).
(We'll have a better understanding of "overall" when we cover amortized analysis.)
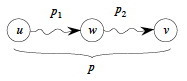
When we study graphs, we'll see that finding the shortest path between two vertices in a graph has optimal substructure: if p = p1 + p2 is a shortest path between u and v then p1 must be a shortest path between u and w (etc.). Proof by cut and paste.
But finding the longest simple path (the longest path not repeating any edges) between two vertices is not likely to have optimal substructure.
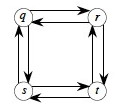
For example, q → s → t → r is longest simple path from q to r, and r → q → s → t is longest simple path from r to t, but the composed path is not even legal: the criterion of simplicity is violated.
Dynamic programming requires overlapping yet independently solveable subproblems.
Longest simple path is NP-complete, a topic we will cover at the end of the semester, so is unlikely to have any efficient solution.
Although we wrote the code both ways, in terms of the order in which solutions are found, dynamic programming first finds optimal solutions to subproblems and then choses which to use in an optimal solution to the problem. It applies when one cannot make the top level choice until subproblem solutions are known.
In Topic 13, we'll see that greedy algorithms work top down: first make a choice that looks best, then solve the resulting subproblem. Greedy algorithms apply when one can make the top level choice without knowing how subproblems will be solved.
Dynamic Programming applies when the problem has these characteristics:
Dynamic programming can be approached top-down or bottom-up:
Both have the same asympotic running time. The top-down procedure has the overhead of recursion, but computes only the subproblems that are actually needed. Bottom-up is used the most in practice.
We problem solve with dynamic programming in four steps:
There is an online presentation focusing on LCS at http://www.csanimated.com/animation.php?t=Dynamic_programming.
In the next Topic 13 we look at a related optimization strategy: greedy algorithms.