ICS 311 #7: Divide & Conquer and Analysis of Recurrences
Prerequisites review
Outline
- Divide & Conquer and Recurrences
- Merge Sort: A Divide & Conquer Strategy
- Brief Comment on Merge Sort Correctness
- Analysis of Merge Sort: Recurrence Relations and Recursion Tree
- Substitution Method
- Recursion Trees
- Master Theorem & Method
Readings and Screencasts
- CLRS Sections 2.3, 4.1, 4.3, 4.4, 4.5 (Sections 4.2 and 4.6 are optional, but may help you understand the material better)
- Screencasts (also in Laulima):
- 2D Merge Sort
- 2E Merge Sort Analysis
- 7A Divide and Conquer
- 7B Substitution Method
- 7C Recursion Trees
- 7D Master Method
Divide & Conquer and Recurrences
Divide & Conquer Strategy
- Divide
- the problem into subproblems that are smaller instances of the same problem.
- Conquer
- the subproblems by solving them recursively. If the subproblems are small
enough, solve them trivially or by "brute force."
- Combine
- the subproblem solutions to give a solution to the original problem.
Recurrences
The recursive nature of D&C leads to recurrences, or functions defined in terms
of:
- one or more base cases, and
- itself, with smaller arguments.
Merge Sort: A Divide & Conquer Strategy
In the case of the Insertion Sort we saw Incremental Strategy for designing algorithms. Another strategy which is very powerfull is to Divide and Conquer:
- Divide
- the problem into subproblems that are smaller instances of the same problem.
- Conquer
- the subproblems by solving them recursively. If the subproblems are small
enough, solve them trivially or by "brute force."
- Combine
- the subproblem solutions to give a solution to the original problem.
Merge Sort (which you should have seen in ICS 211 (Complex Sorting Algorithms)) takes this strategy:
- Divide:
- Given A[p .. r], split the given array into two subarrays A[p .. q] and A[q+1
.. r] where q is the halfway point of A[p .. r].
- Conquer:
- Recursively sort the two subarrays. If they are singletons, we have the
base case.
- Combine:
- Merge the two sorted subarrays with a (linear) procedure Merge that iterates over
the subarrays from the smallest element up to copy the next smallest element
into a result array.
(This is like taking two decks of sorted cards and
picking the next smallest one off to place face-down in a new pile to make
one sorted deck.)
The strategy can be written simply and elegantly in recursive code ...

Here are examples when the input is a power of two, and another example when it is not a power of
two:
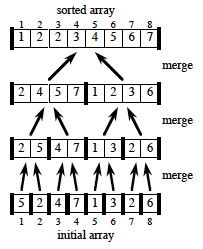

Now let's look in detail at the merge procedure, implemented using ∞ as sentinels
(what do lines 1-2 do? lines 3-9 ? lines 10-17?):
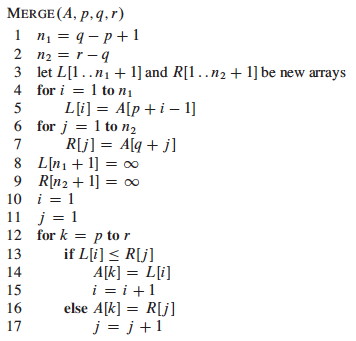
Here's an example of how the final pass of MERGE(9, 12, 16) happens in an array,
starting at line 12. Entries with slashes have had their values copied to either L or R and have not
had a value copied back in yet. Entries in L and R with slashes have been copied back into A.

We can also dance this one: http://youtu.be/XaqR3G_NVoo
Merge Sort Correctness
A loop invariant is used in the book to establish correctness of the Merge
procedure. Since the loop is rather straightforward, we will leave it to the
above example. Once correctness of Merge is established, induction can be
used to show that Merge-Sort is correct for any N.
Analysis of Merge Sort: Recurrence Relations and Recursion Tree

Merge Sort provides us with our first example of using recurrence relations
and recursion trees for analysis.
Analysis of Merge
Analysis of the Merge procedure is straightforward. The first two for loops (lines 4 and
6) take Θ(n1+n2) = Θ(n) time, where
n1+n2 = n. The last for
loop (line 12) makes n iterations, each taking constant time, for Θ(n)
time. Thus total time is Θ(n).
Analyzing Divide-and-Conquer Algorithms
Recurrence equations are used to describe the run time of Divide & Conquer
algorithms. Let T(n) be the running time on a problem of size n.
- If n is below some constant (or often, n=1), we can solve the
problem directly with brute force or trivially in Θ(1) time.
- Otherwise we divide the problem into a subproblems, each
1/b size of the original. Often, as in Merge Sort, a = b =
2.
- We pay cost D(n) to divide the problems and C(n) to combine the
solutions.
- We also pay cost aT(n/b) solving subproblems.
Then the total time to solve a problem of size n by dividing into a problems of
size n/bcan be expressed as:
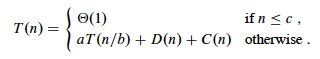
Recurrence Analysis of Merge Sort
Merge-Sort is called with p=1 and r=n. For simplicity, assume
that n is a power of 2. (We can always raise a given n to the next
power of 2, which gives us an upper bound on a tighter Θ analysis.) When
n≥2, the time required is:
- Divide (line 2): Θ(1) is required to compute q as the average of p
and r.
- Conquer (lines 3 and 4): 2T(n/2) is required to recursively solve two
subproblems, each of size n/2.
- Combine (line 5): Merging an n-element subarray takes Θ(n) (this term
absorbs the Θ(1) term for Divide).
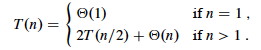
There are several methods to solving recurrences of this form. We will get to them in a minute.
First, let's take a look at another example of an algorithm that utilizes the Divide & Conquer strategy.
Recursive Solution to Maximum Subarray
Suppose you have an array of numbers and need to find the subarray with the maximum sum of
elements in the subarray. (The problem is trival unless there are negative numbers involved.)

The following algorithm is not the fastest known (a linear solution exists), but it illustrates
divide and conquer. The solution strategy, given an array A[low .. high], is:
- Divide
- the subarray into two subarrays of equal size as possible by finding the midpoint mid of
the subarrays.
- Conquer
- by finding a maximum subarray of A[low .. mid] and A[mid+1
.. high].
- Combine
- by also finding a maximum subarray that crosses the midpoint, and using the best solution of
the three (the subarray crossing the midpoint and the best of the solutions in the Conquer step).
The strategy works because any subarray must lie in one of these three positions:
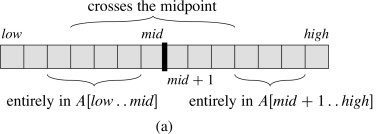
Pseudocode
Recursion will handle the lower and upper halves. The algorithm relies on a helper to find the
crossing subarray. Any maximum subarray crossing the midpoint must include
arrays ending at A[mid] and starting at A[mid+1]:
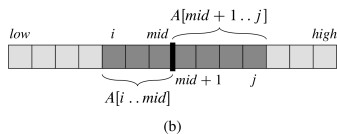
Therefore the pseudocode finds the maximum array on each side and adds them up:

It should be clear that the above is Θ(n). The recursive solution follows.

Check your understanding: Where is the work done? What adds up the values in the left and
right subarrays?
Analysis
The analysis relies on the simplifying assumption that the problem size is a power of 2 (the same
assumption for merge sort). Let T(n) denote the running time of FIND-MAXIMUM-SUBARRAY on a
subarray of n elements.
- Base case:
- Occurs when high equals low, so that n=1: it just returns in Θ(1)
time.
- Recursive Case (when n>1):
-
- Dividing takes Θ(1) time.
- Conquering solves two subproblems, each on an array of n/2 elements:
2T(n/2).
- Combining calls FIND-MAX-CROSSING-SUBARRAY, which takes Θ(n), and some
constant tests: Θ(n) + Θ(1).
T(n) = Θ(1) + 2T(n/2) + Θ(n) + Θ(1)
= 2T(n/2) + Θ(n).
The resulting recurrence is the same as for merge sort:
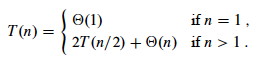
So how do we solve these recurrences? We have three methods: Substitution, Recursion Trees, and the Master
Method.
Substitution Method
Don't you love it when a "solution method" starts with ...
- Guess the solution!
- Use induction to find any unspecified constants and show that the solution works.
(You should have learned induction in ICS 141 (Induction & Recursion). If you don't remember it, go and review it now.
You can also read these notes to refresh your memory.)
Recursion trees (next section) are one way to guess solutions. Experience helps too. For example,
if a problem is divided in half we may expect to see lg n behavior.
As an example, let's solve the recurrence for merge sort and maximum subarray. We'll start with an
exact rather than asymptotic version:

- Guess: T(n) = n lg n + n. (Why this
guess?)
- Induction:
- Basis:
- n = 1 ⇒ n lg n + n = 1
lg 1 + 1 = 1 = T(n).
- Inductive Step:
- Inductive hypothesis is that T(k) = k lg k + k for all k
< n. We'll use k = n/2, and show that this implies that T(n) =
n lg n + n. First we start with the definition of T(n); then we
substitute ...

Induction would require that we show our solution holds for the boundary conditions. This is
discussed in the textbook.
Normally we use asymptotic notation rather than exact forms:
- writing T(n) = 2T(n/2) + O(n),
- assuming T(n) = O(1) for sufficiently small n,
- not worrying about boundary or base cases, and
- writing solutions in asymptotic notation, e.g., T(n) = O(n lg n).
If we want Θ, sometimes we can prove big-O and Ω separately "squeezing" the Θ
result.
But be careful when using asymptotic notation. For example, suppose you have the case where
a=4 and b=4 and want to prove T(n)
= O(n) by guessing that T(n) ≤ cn and writing:
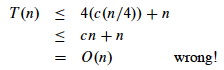
One must prove the exact form of the inductive hypothesis, T(n) ≤ cn.
See the text for other strategies and pitfalls.
Problems 4.3-1 and 4.3-2 are good practice problems.
Recursion Trees
Recursion trees provide an intuitive understanding of the above result. Although recursion trees can be considered a proof format, for a formal analysis, they must be applied very carefully. Instead, they are used to generate
guesses that are verified by substitution.
To construct the recursion tree, do the following:
- Construct a tree, where each node represents the cost of a single subproblem in the set of recursive invocations
- Sum the costs with each level of the tree to obtain per-level costs
- Sum the costs across levels for the total cost.
Let's choose a constant c that is the largest of all the constant
costs in the algorithm (the base case and the divide steps). Then the recurrence
can be written:
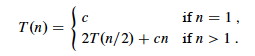
It costs cn to divide the original problem in half and then to merge
the results. We then have to pay cost T(n/2) twice to solve the
subproblems:
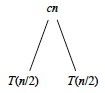
For each of the two subproblems, n/2 is playing the role of n
in the recurrence. So, it costs cn/2 to divide and then merge the
n/2 elements, and T(n/4) to solve the subproblems:
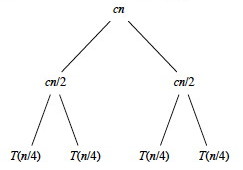
If we continue in this manner we eventually bottom out at problems of size 1:
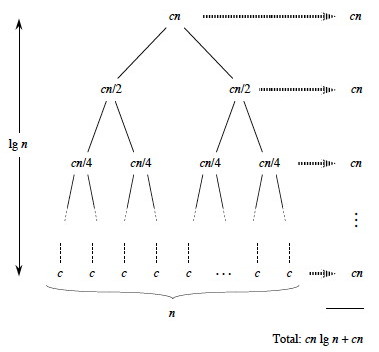
Notice that if we sum across the rows each level has cost cn. So, all
we have to do is multiply this by the number of levels. Cool,
huh?
But how many levels are there? A little thought (or a more formal inductive
proof you'll find in the book) shows that there are about (allowing for the fact
that n may not be a power of 2) lg(n)+1 levels of the tree. This is
because you can only divide a power of two in half as many times as that power
before you reach 1, and n = 2lg(n). The 1 counts
the root node before we start dividing: there is always at least one level.
Questions? Does it make sense, or is it totally mysterious?
A More Complex Example
A more complex example is developed in the textbook for
T(n) = 3T(n/4) + Θ(n2)
which is rewritten (making the implied constant explicit) as
T(n) = 3T(n/4)+ cn2
node, T(n) = 3T(n/4) +cn2.
We can develop the recursion tree in steps, as follows. First, we begin the tree with its root:
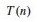
Now let's branch the tree for the three recursive terms 3T(n/4). There are three children
nodes with T(n/4) as their cost, and we leave the cost cn2 behind at the
root node:
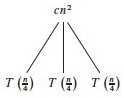
We repeat this for the subtrees rooted at each of the nodes for T(n/4): Since each of
these costs 3T((n/4)/4) +c(n/4)2, we make three branches, each costing
T((n/4)/4) = T(n/16), and leave the c(n/4)2 terms behind at
their roots:
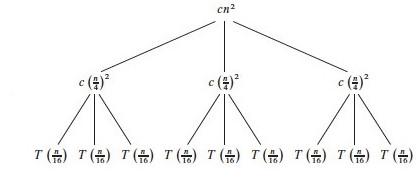
Continuing this way until we reach the leaf nodes where the recursion ends at trivial subproblems
T(1), the tree looks like this:
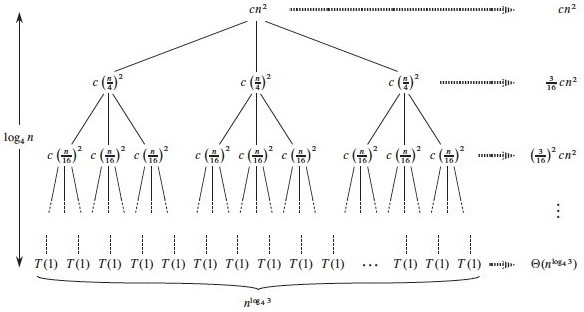
Subproblem size for a node at depth i is n/4i, so
the subproblem size reaches n = 1 when (assuming n a power of 4)
n/4i = 1, or when i = log4n.
Including i = 0, there are log4n + 1 levels.
Each level has 3i nodes.
Substituting i = log4n into 3i, there are
3log4n nodes in the bottom level.
Using alogbc = clogba, there are
nlog43 in the bottom level (not n, as in the previous
problem).
Adding up the levels, we get:
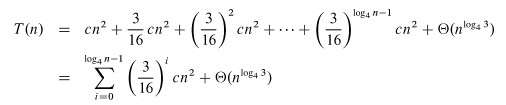
It is easier to solve this summation if we change the equation to an inequality and let the
summation go to infinity (the terms are decreasing geometrically), allowing us to apply equation
A.6 (∑k=0,∞xk = 1/1-x):
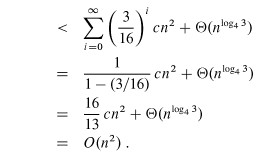
Additional observation: since the root contributes cn2, the root dominates the
cost of the tree, and the recurrence must also be Ω(n2), so we have
Θ(n2).
Please see the text for an example involving unequal subtrees. For practice, exercises 4.4-6 and
4.4-9 have solutions posted on the book's web site.
Master Theorem & Method
If we have a divide and conquer recurrence of the form
T(n) = aT(n/b) + f(n)
where a ≥ 1, b > 1, and f(n) > 0 is asymptotically positive,
then we can apply the master method, which is based on the master theorem. We
compare f(n) to nlogba under asymptotic (in)equality:
Case 1: f(n) = O(nlogba - ε) for some constant
ε > 0.
(That is, f(n) is polynomially smaller than nlogba.)
Solution: T(n) = Θ(nlogba).
Intuitively: the cost is dominated by the leaves.
Case 2: f(n) = Θ(nlogba), or more generally
(exercise 4.6-2): f(n) =
Θ(nlogba lgkn), where k ≥ 0.
(That is, f(n) is within a polylog factor of nlogba,
but not smaller.)
Solution: T(n) =
Θ(nlogba lgn), or T(n) =
Θ(nlogba lgk+1n) in the more general case.
Intuitively: the cost is nlogba lgkn at each
level and there are Θ(lgn) levels.
Case 3: f(n)= Ω(nlogba + ε) for some constant
ε > 0, and f(n) satisfies the regularity condition af(n/b) ≤
cf(n) for some constant c<1 and all sufficiently large n.
(That is, f(n) is polynomially greater than nlogba.)
Solution: T(n) = Θ(f(n)),
Intuitively: the cost is dominated by the root.
Important: there are functions that fall between the cases!
Examples
T(n) = 5T(n/2) + Θ(n2)
- a = 5, b = 2, f(n) = n2
- Compare n2 to nlogba = nlog25.
- log25 - ε = 2 for some constant ε > 0.
- Case 1: T(n) = Θ(nlg 5).
T(n) = 27T(n/3) + Θ(n3 lg n)
- a = 27, b = 3, f(n) = n3 lg n
- Compare n3 lg n to nlog327
= n3
- Case 2 with k = 1: T(n) = Θ(n3 lg2 n).
T(n) = 5T(n/2) + Θ(n3)
- a = 5, b = 2, f(n) = n3
- Compare n3 to nlog25
- log25 + ε = 3 for some constant ε > 0.
- Check regularity condition (not necessary since f(n) is polynomial:
af(n/b) = 5(n/2)3 = 5n3/8 ≤
cn3 for c = 5/8 < 1.
- Case 3: T(n) = Θ(n3).
T(n) = 27T(n/3) + Θ(n3 / lg n)
- a = 27, b = 3, f(n) = n3 / lg n
- Compare n3/lg n to nlog327 =
n3
- Cases 1 and 3 won't work as no ε can adjust the exponent of 3 to account for the
1/lgn = lg−1n factor. Only hope is Case 2.
- But n3/lg n = n3 lg−1n ≠
Θ(n3 lgk n) for any k ≥ 0.
- Cannot use master method.
- Could try substitution, which requires a guess. Drawing the
full recursion tree would be tedious, but perhaps visualizing its general form would
help with the guess.
Conclusions and One More Animation
Recapitulating our conclusions, we have seen that Insertion sort is quick on
already sorted data, so it works well when incrementally adding items to an
existing list. Due to its simplicity it is a good choice when the sequence to
sort will always be small. But for large inputs Merge Sort will be faster than
Insertion Sort, as n2 grows much faster than nlg(n).
Each sort algorithm has different strengths and weaknesses, and performance
depends on the data. Some of these points are made in the following
visualizations (also watch for patterns that help you understand the
strategies):
http://www.sorting-algorithms.com/
(set to 50 elements)
Nodari Sitchinava (based on material by Dan Suthers)
Images are from the instructor's material for Cormen et al. Introduction to Algorithms, Third
Edition.