Semantic File Systems: A Simpler Alternative
Semantic file systems are an alternative to traditional hierarchical file
systems. They attempt to organise files and/or data by semantic meta-data rather
than just by position in a hierarchical file path. Two approaches to implementing
semantic file Systems are "augmented" and "integrated",
which differ on the level at which they attempt to implement the semantic file
system; as an overlay on, or as a replacement to, an existing filesystem. This
article takes a look at the challenges of implementing a semantic file system,
and some of the user interface issues that arise, since semantic file systems
are all about trying to present the user with a more convenient interface to
access their data.
Hierarchical File Systems
Hierarchical file systems are familiar to most modern computer users. User
data is stored in file objects, which are themselves organised into different
directories. A special type of file that contains a list of other files. Directories
can also contain other directories in a nested fashion, allowing a hierarchical,
or tree-like, structure to be created. Specific files can then be referred to
uniquely by their path; a string of directory names that traces a path through
the tree-structure to their location, e.g.
In UNIX
/usr/bin/ls.exe
In MS-DOS
c:/windows/config.sys
 The
figure on the left shows the traditional structure of a hierarchical file system.
At the top is a root directory ('/' in UNIX, a drive letter followed by ':/'
in MS-DOS), in which directories and files are placed in a nested hierarchy.
Links may cross this tree structure, potentially allowing files to exist in
more than one directory (hard/soft-links in UNIX, short-cuts in MS-DOS).
The
figure on the left shows the traditional structure of a hierarchical file system.
At the top is a root directory ('/' in UNIX, a drive letter followed by ':/'
in MS-DOS), in which directories and files are placed in a nested hierarchy.
Links may cross this tree structure, potentially allowing files to exist in
more than one directory (hard/soft-links in UNIX, short-cuts in MS-DOS).
It is interesting to consider the motivation behind the hierarchical file system.
Given a small number of files, they can all be stored in a single location.
However this leads to naming conflicts. Two files can be referred to by the
same name, but this presents a problem for the system to understand which file
a user might be referring to when they issue a command to manipulate a particular
file. The introduction of directories removes this problem by providing a context
for each file reference. Individual files can now have identical names such
as "notes.txt", but the system can now disambiguate between the two
of them using two different file 'paths', e.g.
/home/sam/projects/sequencer/notes.txt
/home/sam/projects/database/notes.txt
Thus files can be placed into directories that indicate some common feature
of those files, e.g. that they all relate to a particular user or a particular
project. The hierarchical file system is extremely useful in supporting this
abstraction, but as the number of files and directories increase it becomes
increasingly difficult to navigate, i.e. the cognitive load of remembering the
precise path of a particular path increases as the size and complexity of the
directory tree increases.
There is also the problem of where to place new files in an existing structure.
By their very nature files have many possible associations to different projects,
users, programming languages, events and so forth. This issue can be resolved
somewhat by creating links or shortcuts so that new files can be placed in multiple
locations, but the granularity here, i.e. one command to create one link, makes
it burdensome for the user to make multiple associations for each new file.
Personal experience suggests that users tend to chose a single "location"
(or rather "path") that best represents the file, and then continue
with their current work, rather than go to the effort of creating multiple links
so that the file is easy to discover in future.
Thus the common experience for heavy computer users is an increasingly complex
hierarchy, with files becoming more and more difficult to locate. The common
response is search functionality; UNIX provides the "find" command,
and GUI file explorers routinely provide search functionality of varying levels
of sophistication. The problem is that search is slow over a large file system,
and the search is restricted to things like the file name or last-modified time.
This means that the file name can become overloaded with additional information
about the file, which becomes a burden as a reference in a context where the
file referent is clear e.g. /home/sam/projects/database/schema/planning/database_project_schema_planning_notes.txt.
Semantic File Systems
Semantic file systems try to address some of the problems faced by hierarchical
file systems as they increase in size and complexity. In a semantic file system,
files may still be accessed through "path" criteria, but can also
be accessed via "semantic" attributes; for example a file might be
referred to by the path "/home/sam/notes.txt", but also that it was
authored by the user 'sam', or is related to project X. This is different from
pure search in that the semantic meta-data is presented as part of the file
system rather than as an afterthought. In a semantic file system navigation
is now through a space of semantic attributes as opposed to a directory hierarchy.
This doesn't mean that the directory hierarchy and associated path names have
to be discarded, just that there is now greater support for alternatives.
Augmented vs. Integrated SFS
Achieving a semantic file system structure requires one of two approaches,
either an augmented or an integrated approach. An integrated approach such as
the SHORE system of the University of Wisconsin. An integrated approach provides
a complete solution to all of the issues that have to be addressed to create
a semantic file system [need a list of those issues?], but has the disadvantage
that the underlying operating system (OS) must be changed. The alternative is
an augmented approach such as the SFS/Discover system from MIT. An augmented
approach layers the semantic file system functionality over the top of an existing
OS. This means that the user's current file access capabilities are unaffected,
i.e. the user can work with their existing files in their existing formats,
and their existing attributes such as last-modified time. In addition an augmented
system can take advantage of ongoing improvements to the underlying OS and this
means less work needs be spent implementing unrelated functions in the SFS overlay;
however the downside is that these same changes in the underlying OS may break
the augmented system, and that the OS will not necessarily provide the augmented
layer with timely updates. For example, the OS will not necessarily notify the
augmented system with information such as changes to file names or locations.
As a result the augmented system may require a custom file polling scheme that
periodically checks for updates to the filesystem.
SFS/Discover
SFS/Discover (Gifford et al., 1991) is a file system layer on top of NFS (Network
File System) supporting both virtual directories and file content extraction.
In order to deal with the problem of synchronising with the underlying file
system all access is routed through NFS compatible SFS commands. Navigation
commands dynamically generate directories based upon file attributes associated
with, or extracted from, the existing files in the system. These navigation
commands are queries on specific file attributes, which result in an appropriate
directory view of the information. File specific content extractors called transducers
extract different meta-data attributes depending on whether the file contains
emails, c-code or other identifiable formats. Examples of the system operation
are shown below:
% cd /sfs/exports:/lookup_fault
% ls -F
virtdir_query.c@ virtdir_query.o@
% cd ext:/c
% ls -F
virtdir_query.c@
%
|
This example shows how SFS/Discover overloads the "cd" command to
perform a query as to which files have the value "lookup_fault" assigned
to their "export" attribute. The query is then refined with another
overloaded "cd" command which further narrows the search to those
files that have the value "c" assigned to their "ext"attribute,
i.e. files of the format *.c. Using "cd" to add an additional query
term assumes an implicit AND operation.
% ls -F /sfs/owner:
jones/ smith/ root/
%
% ls -F /sfs/owner:/smith
bio.txt@ paper.tex@ prop.tex@
%
% ls -F /sfs/owner:/smith/text:/resume
bio.txt@
%
|
This example shows how SFS/Discover overloads the "ls" command to
perform a query that returns all the possible values for a particular meta-data
attribute, in this case the attribute "owner". In addition we see
how multiple attribute queries can be combined into a single command line, using
an implicit AND operation.
% ls -F /sfs/field:
author:/ exports:/ owner:/ text:/
category:/ ext:/ priority:/ title:/
date:/ imports:/ subject:/ types:/
dir:/ name:/
%
% ls -F /sfs/field:/text:/semantic/owner:/jones
mail.txt@ paper.tex@ prop.tex@
|
Finally this example shows us how "ls" can be used to display all
of the different possible meta-data attributes.
Location Metaphor
While the SFS/Discover syntax might be a little difficult to understand at
first glance, it is making use of a very powerful metaphor in order to transform
the search process into one of incremental navigation. While the original inspiration
for hierarchical file systems may have been a filing cabinet and some GUIs may
make them look like one, directories can also provide a strong sense of location
to the user. Changing directories when working from a command line interface
has a natural sense of working in a particular location. Creating a sub-directory
within a directory can be seen as creating a new location that can then be entered.
Entering this new location, it follows intuitively that files created here should
be stored in this location. The approach that a semantic file system offers
above and beyond more structured support for file meta-data is to maintain the
sense of navigation through a space, but to remove the restriction of navigating
only up and down a tree structure. A hypothetical implementation that emphasized
this aspect of navigation even more than SFS/Discover might look something like
the following:
{work} {sequencer-project} {john}
{java} % ls
RandomSequencer.java SequencerTMVC.java
SimpleAccordianSequencer.java SimpleAtkinsonSequencer.java
State.java
{work} {sequencer-project} {john} {java}
% rc sequencer-project
{work} {john} {java} % ac database-project
DBAccessLite.java DBOperation.java
{work} {database-project} {john} {java}
% edit DBAccessLite.java
{work} {database-project} {john} {java}
% ac DBAccessLite.java j2me
{work} {database-project} {john} {java} {j2me}
% ls
ExampleTestMidlet.java DBAccessLite.java
|
This hypothetical example uses even simpler meta-data than SFS/Discover, preferring
single keywords, rather than attribute value pairs. The red curly bracketed
words at the begining of each command prompt indicate the current "location".
Rather than specifying a path, these keywords indicate our current location
in "concept space". Typing "ls" at the command prompt returns
all the files that are associated with the keywords currently displayed. Additional
commands such as "rc" (remove-concept) can be used to remove a concept
from the current location, and effectively broaden the view of files that "ls"
will return. The order of the keywords is not important, as it is in a path
string, and so one simply need remember the set of associated keywords to locate
a file, rather than an unforgiving path string. Another command "ac"
allows keywords to be associated with files, and add that keyword to the current
location. Naturally creating a new file in a particular location leads to the
automatic association of the current keywords as meta-data to that file.
Issues
The SFS/Discover system was never made publicly available and the above system
is only a sketch, but there are certain key issues that arise when we try to
consider such a semantic navigation system:
1. Should meta-data be simple keywords, or more complex attribute-value pairs,
or even allow weights?
2. Should thesaurus like relations (e.g. broader/narrower) be included such
that pseudo-hierarchies can be threaded into the association space
3. When querying/navigating over a set of concepts should an implicit AND or
implicit OR be used? Implicit AND makes more sense, but should more boolean
options be provided.
4. How can keyword/concept divergence be avoided, e.g. files getting separated
over variations in spelling and meaning, e.g. “image”, “images”, “pictures”
& “graphics”?
5. Is fuzzy/wildcard searching over concepts important? Does this erode the
navigation metaphor?
6. To what extent should concepts/keywords be automatically extracted from files?
There are many possible approaches to the above issues. In terms of avoiding
divergence of the keyword/concept space it would seem to make sense to display
a list of existing similar keywords when the user tries to create new ones.
However each of these issues is addressed it would also seem possible to achieve
at least a degree of this kind of navigation in an existing file-system without
any overlay at all. Consider the following diagram:
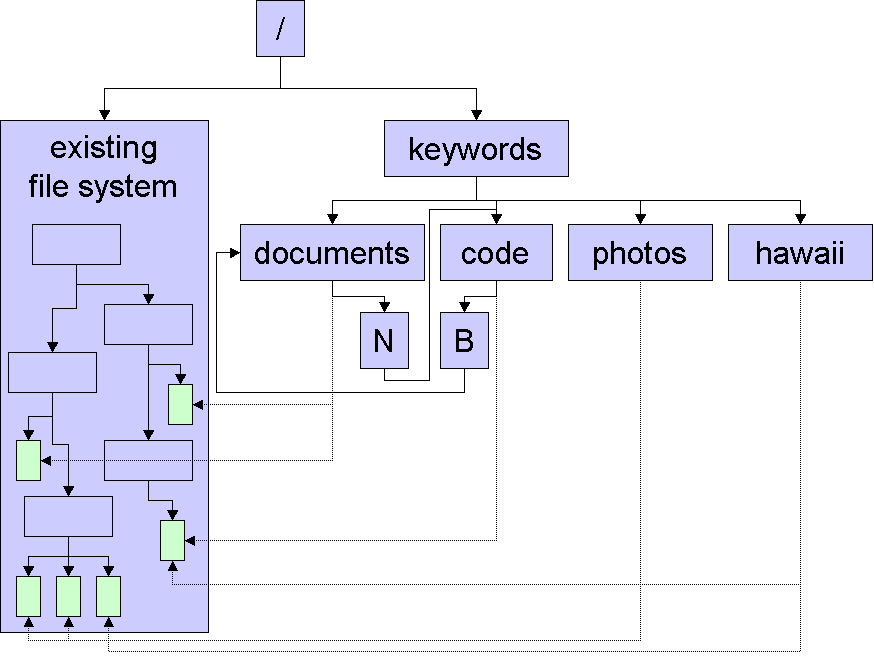
In this diagram we see the addition of a /keywords/ directory to the root directory
in an existing hierarchical file system. This semantic file system exists completely
in parallel to the hierarchical file tree, but the tree is parsed and hard links
are created for all files so that they will appear in a sub-directory of the
/keywords/ directory for each element of their path. Thus for the file "/home/sam/java/notes.txt"
would have hard links created in the directories "/keywords/home/",
"/keywords/sam/", "/keywords/java/". It would then be possible
to simply inspect all the files that appeared in one "bin" directory
or another. The "N" and "B" sub-directories indicate how
thesaurus-like broader & narrower relations could be implemented between
different keywords.
Having created this kind of structure, it would then be possible for the user
to go on adding additional meta-data in the form of more hard links. The advantage
of using the hard links is that they prevent the files being deleted, and so
changes in the hierarchical portion of the system do not lead to inaccurate
meta-data. Naturally a new sort of semantic-delete operation would be required,
but search and meta-data manipulation in the above scheme would not be difficult
as indicated by the following shell scripts:
#!/usr/bin/sh
# ------------------
# search_keywords.sh
# ------------------
if [ $2 ]
then
ls -l /keywords/$1 /keywords/$2
| sort | uniq -d
elif [ $1 ]
then
ls -l /keywords/$1
else
echo "Usage: search_keywords.sh
keyword1 <keyword2>"
fi
|
This script allows the user to find all the files associated with up to two
keywords (implicit AND)
#!/usr/bin/sh
# ------------------
# keywords.sh
# ------------------
if [ -z $1 ]
then
echo "Usage: keywords.sh
file"
else
inode=`ls -i $1 | awk '{
print $1 }'`
find /keywords -inum $inode
| awk -F / '{ print $3 }'
fi |
This script allows the user to find all the keywords associated with a particular
file. Notice that we search via the file's inode reference, so that even if
the original file undergoes a name change, we will still see all the meta-data
associated with the file.
#!/usr/bin/sh
# ------------------
# add_keywords.sh
# ------------------
if [ $3 ]
then
mkdir /keywords/$3 >
/dev/null 2>&1
ln $1 /keywords/$3 >
/dev/null 2>&1
mkdir /keywords/$2 >
/dev/null 2>&1
ln $1 /keywords/$2 >
/dev/null 2>&1
keywords.sh $1
elif [ $2 ]
then
mkdir /keywords/$2 >
/dev/null 2>&1
ln $1 /keywords/$2 >
/dev/null 2>&1
keywords.sh $1
else
echo "Usage: add_keyword
file keyword1 <keyword2>"
fi |
This script allows the user to add up to two keywords to a file. Once the new
keyword has been added, all the keywords currently associated with the file
are displayed
sam@Erech
/d/user/photos
$ add_keyword.sh guam-beach.gif photos guam
sam@Erech /d/user/photos
$ add_keyword.sh guam-beach.gif photos guam
guam
photos
sam@Erech /d/user/photos
$ add_keyword.sh guam-beach.gif beach
beach
guam
photos
sam@Erech /d/user/photos
$ search_keywords.sh photos guam
-rwx------+ 4 sam 18664 Aug 6 09:47 guam-beach.gif
|
The system operates as shown above. Another shell-script could be used to perform
the initial parsing of a file hierachy, but the three scripts above are enough
to start semantic browsing of files. The location metaphor is not strongly provided
as yet, since there needs to be some way to store location "state",
which could presumably be achieved by more sophisticated shell scripts that
updated a location file in the users home directory, or modifications to the
shell itself. It would be desirable to avoid modification to the shell if possible,
since it would be nice to be shell-independent. The contents of a "location
state" file could be displayed as part of the command prompt to give a
sense of location.
One particular concern is scalability. At the moment the search_keywords.sh
script does uses a "find" operation over the entire /keywords/ directory.
This may well be impractical as the number of files increases, but we are limited
to this for current POSIX file systems since inodes only store a reference count
of the number of times they are linked to, and not the identity of the directory
linking to them. It might be possible to use something like Linux extended file
attributes so that inodes would also store information about who was linking
to them, and make retrieving that data a simple lookup rather than a search.
The diagram below shows how the links are currently implemented:

Linux extended attributes allow arbitrary attribute value pairs to be stored
in association with files, and are used to implement additional functionality
such as security features. The extended attributes are supported on ext2, ext3,
ReiserFS and a few other file systems. Extended file attributes can be accessed
and manipulated using the commands getfattr and setfattr, that operate as follows:
setfattr -n hardlinking.directory -v guam guam-beach.gif
setfattr -n hardlinking.directory -v beach guam-beach.gif
getfattr -d guam-beach.gif
1: # file: /home/sam/photos/
2: hardlinking.directory0="guam"
3: hardlinking.directory1="beach"
4: hardlinking.directory2="photos"
5: ...
|
Although this could be seen as storing the file meta-data directly in the extended
attributes the /keywords/ directory and associated sub-structure is still important
as it supports searching over the files for different meta-data, something not
explicitly supported by extended attributes.
Related Work
Gnome Storage: http://www.gnome.org/~seth/storage/
Witme: http://witme.sourceforge.net/
Concept Analysis: http://www.inria.fr/rrrt/rr-3942.html
Semantic File Systems Comparison: http://www.objs.com/survey/OFSExt.htm
Linux Extended Attributes: http://acl.bestbits.at/man/man.shtml