Multithreading is of course a crucial topic for modern computing. This is just a brief introduction to this topic and I encourage you to explore it further by taking courses we offer on this topic. There are two granularities: (1) parallel algorithms (ICS 443/643) or multithreading a single algorithm, which is our emphasis here and in the textbook; (2) and scheduling and managing multiple algorithms, each running concurrently in their own thread and possibly sharing resources, as studied in courses on operating systems (ICS 332/612) and concurrent and high performance computing (ICS 432/632).
Parallel Machines are getting cheaper and in fact are now ubiquitous ...
Static threading: abstraction of virtual processors. But rather than managing threads explicitly, our model is dynamic multithreading in which programmers specify opportunities for parallelism and a concurrency platform manages the decisions of mapping these to static threads (load balancing, communication, etc.).
Three keywords are added, reflecting current parallel-computing practice:
These keywords specify opportunities for parallelism without affecting whether the corresponding sequential program obtained by removing them is correct. We exploit this in analysis.
For illustration, we take a really slow algorithm and make it parallel. (There are much better ways to compute Fibonacci numbers.) Here is the definition of Fibonacci numbers:
F0 = 0.
F1 = 1.
Fi = Fi-1 + Fi-2, for i ≥ 2.
Here is a recursive non-parallel algorithm for computing Fibonacci numbers modeled on the above definition, along with its recursion tree:


Fib has recurrence relation T(n) = T(n - 1) + T(n - 2) + Θ(1), which has the solution \(T(n) = \Theta(F_n) = \Theta\left(\frac{\left(\frac{1+\sqrt{5}}{2}\right)^n - \left(\frac{1-\sqrt{5}}{2}\right)^n}{\sqrt{5}}\right)\) (see the text for substitution method proof). This grows exponentially in n, so it's not very efficient. (A straightforward iterative algorithm is much better.)
Noticing that the recursive calls operate independently of each other, let's see what improvement we can get by computing the two recursive calls in parallel. This will illustrate the concurrency keywords and also be an example for analysis:

Notice that without the keywords it is still a valid serial program.
Logical Parallelism: The spawn keyword does not force parallelism: it just says that it is permissible. A scheduler will make the decision concerning allocation to processors.
However, if parallelism is used, sync must be respected. For safety, there is an implicit sync at the end of every procedure.
We will return to this example when we analyze multithreading.
Scheduling parallel computations is a complex problem: see the text for some theorems concerning the performance of a greedy centralized scheduler (i.e., one that has information on the global state of computation, but must make decisions on-line rather than in batch).
Professor Henri Casanova does research in this area, and would be an excellent person to talk to if you want to get involved.
First we need a formal model to describe parallel computations.
We will model a multithreaded computation as a computation dag (directed acyclic graph) G = (V, E); an example for P-Fib(4) is shown:

Vertices in V are instructions, or strands = sequences of non-parallel instructions.
Edges in E represent dependencies between instructions or strands: (u, v) ∈ E means u must execute before v.
A strand with multiple successors means all but one of them must have spawned. A strand with multiple predecessors means they join at a sync statement.
If G has a directed path from u to v they are logically in series; otherwise they are logically parallel.
We assume an ideal parallel computer with sequentially consistent memory, meaning it behaves as if the instructions were executed sequentially in some full ordering consistent with orderings within each thread (i.e., consistent with the partial ordering of the computation dag).
We write TP to indicate the running time of an algorithm on P processors. Then we define these measures and laws:
T1 = the total time to execute an algorithm on one processor. This is called work in analogy to work in physics: the total amount of computational work that gets done.
An ideal parallel computer with P processors can do at most P units of work in one time step. So, in TP time it can do at most P⋅TP work. Since the total work is T1, P⋅TP ≥ T1, or dividing by P we get the work law:
TP ≥ T1 / P
The work law can be read as saying that the speedup for P processors can be no better than the time with one processor divided by P.
T∞ = the total time to execute an algorithm on an infinite number of processors (or, more practically speaking, on just as many processors as are needed to allow parallelism wherever it is possible).
T∞ is called the span because it corresponds to the longest time to execute the strands along any path in the computation dag (the biggest computational span across the dag). It is the fastest we can possibly expect -- an Ω bound -- because no matter how many processors you have, the algorithm must take this long.
Hence the span law states that a P-processor ideal parallel computer cannot run faster than one with an infinite number of processors:
TP ≥ T∞
This is because at some point the span will limit the speedup possible, no matter how many processors you add.
What is the work and span of the computation dag for P-Fib shown?
The ratio T1 / TP defines how much speedup you get with P processors as compared to one.
By the work law, TP ≥ T1 / P, so T1 / TP ≤ P: one cannot have any more speedup than the number of processors.
When the speedup T1 / TP = Θ(P) we have linear speedup, and when T1 / TP = P we have perfect linear speedup.
The ratio T1 / T∞ of the work to the span gives the potential parallelism of the computation. It can be interpreted in three ways:
This latter point leads to the concept of parallel slackness,
(T1 / T∞) / P = T1 / (P⋅T∞),
the factor by which the parallelism of the computation exceeds the number of processors in the machine. If slackness is less than 1 then perfect linear speedup is not possible: you have more processors than you can make use of. If slackness is greater than 1, then the work per processor is the limiting constraint and a scheduler can strive for linear speedup by distributing the work across more processors.
What is the parallelism of the computation dag for P-Fib shown previously? What are the prospects for speedup at *this* n? What happens to work and span as n grows?
Analyzing work is simple: ignore the parallel constructs and analyze the serial algorithm. For example, the work of P-Fib(n) is T1(n) = T(n) = Θ(Fn). Analyzing span requires more work.
If in series, the span is the sum of the spans of the subcomputations. (This is similar to normal sequential analysis.)
If in parallel, the span is the maximum of the spans of the subcomputations. (This is where analysis of multithreded algorithms differs.)

Returning to our example, the span of the parallel recursive calls of P-Fib(n) is:
T∞ (n) = max(T∞(n−1), T∞ (n−2)) + Θ(1)
= T∞(n−1) + Θ(1).
which has solution Θ(n).
The parallelism of P-Fib(n) in general (not the specific case we computed earlier) is T1(n) / T∞ = Θ(Fn/n), which grows dramatically, as Fn grows much faster than n.
There is considerable parallel slackness, so above small n there is potential for near perfect linear speedup: there is likely to be something for additional processors to do.
So far we have used spawn, but not the parallel keyword, which is used with loop constructs such as for. Here is an example.
Suppose we want to multiply an n x n matrix A = (aij) by an n-vector x = (xj). This yields an n-vector y = (yi) where:

The following algorithm does this in parallel:

The parallel for keywords indicate that each iteration of the loop can be executed concurrently. (Notice that the inner for loop is not parallel; a possible point of improvement to be discussed.)
It is not realistic to think that all n subcomputations in these loops can be spawned immediately with no extra work. (For some operations on some hardware up to a constant n this may be possible; e.g., hardware designed for matrix operations; but we are concerned with the general case.) How might this parallel spawning be done, and how does this affect the analysis?
This can be accomplished by a compiler with a divide and conquer approach, itself implemented with parallelism. The procedure shown below is called with Mat-Vec-Main-Loop(A, x, y, n, 1, n). Lines 2 and 3 are the lines originally within the loop.


The computation dag is also shown. It appears that a lot of work is being done to spawn the n leaf node computations, but the increase is not asymptotic.
The work of Mat-Vec is T1(n) = Θ(n2) due to the nested loops in 5-7.
Since the tree is a full binary tree, the number of internal nodes is 1 fewer than the leaf nodes, so this extra work is also Θ(n).
So, the work of recursive spawning contributes a constant factor when amortized across the work of the iterations.
However, concurrency platforms sometimes coarsen the recursion tree by executing several iterations in each leaf, reducing the amount of recursive spawning.
The span is increased by Θ(lg n) due to the tree. In some cases (such as this one), this increase is washed out by other dominating factors (e.g., the doubly nested loops).
Returning to our example, the span is Θ(n) because even with full utilization of parallelism the inner for loop still requires Θ(n). Since the work is Θ(n2) the parallelism is Θ(n). Can we improve on this?
Perhaps we could make the inner for loop parallel as well? Compare the original to this revised version:

Would it work? We need to introduce a new issue ...
Deterministic algorithms do the same thing on the same input; while nondeterministic algorithms may give different results on different runs.
The above Mat-Vec' algorithm is subject to a potential problem called a determinancy race: when the outcome of a computation could be nondeterministic (unpredictable). This can happen when two logically parallel computations access the same memory and one performs a write.
Determinancy races are hard to detect with empirical testing: many execution sequences would give correct results. This kind of software bug is consequential: Race condition bugs caused the Therac-25 radiation machine to overdose patients, killing three; and caused the North American Blackout of 2003.

For example, the code shown below might output 1 or 2 depending on the order in which access to x is interleaved by the two threads:

After we understand that simple example, let's look at our matrix-vector example again:

Here is an algorithm for multithreaded matrix multiplication, based on the T1(n) = Θ(n3) algorithm:

How does this procedure compare to MAT-VEC-WRONG? Is is also subject to a race condition? Why or why not?
The span of this algorithm is T∞(n) = Θ(n), due to the path for spawning the outer and inner parallel loop executions and then the n executions of the innermost for loop. So the parallelism is T1(n) / T∞(n) = Θ(n3) / Θ(n) = Θ(n2)
Could we get the span down to Θ(1) if we parallelized the inner for with parallel for?
Here is a parallel version of the divide and conquer algorithm from Chapter 4:

See the text for analysis, which concludes that the work is Θ(n3), while the span is Θ(lg2n). Thus, while the work is the same as the basic algorithm the parallelism is Θ(n3) / Θ(lg2n), which makes good use of parallel resources.
Divide and conquer algorithms are good candidates for parallelism, because they break the problem into independent subproblems that can be solved separately. We look briefly at merge sort.
The dividing is in the main procedure MERGE-SORT, and we can parallelize it by spawning the first recursive call:

MERGE remains a serial algorithm, so its work and span are Θ(n) as before.
The recurrence for the work MS'1(n) of MERGE-SORT' is the same as the serial version:

The recurrence for the span MS'∞(n) of MERGE-SORT' is based on the fact that the recursive calls run in parallel, so there is only one n/2 term:

The parallelism is thus MS'1(n) / MS'∞(n) = Θ(n lg n / n) = Θ(lg n).
This is low parallelism, meaning that even for large input we would not benefit from having hundreds of processors. How about speeding up the serial MERGE?
MERGE takes two sorted lists and steps through them together to construct a single sorted list. This seems intrinsically serial, but there is a clever way to make it parallel.
A divide-and-conquer strategy can rely on the fact that they are sorted to break the lists into four lists, two of which will be merged to form the head of the final list and the other two merged to form the tail.
To find the four lists for which this works, we

The text presents the BINARY-SEARCH pseudocode and analysis of Θ(lg n) worst case; this should be review for you. It then assembles these ideas into a parallel merge procedure that merges into a second array Z at location p3 (r3 is not provided as it can be computed from the other parameters):
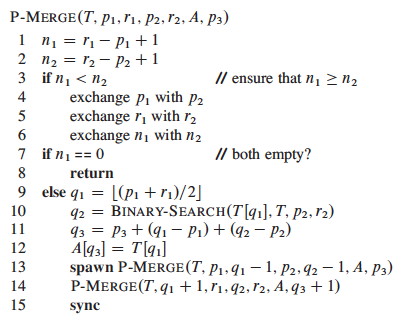
My main purpose in showing this to you is to see that even apparently serial algorithms sometimes have a parallel alternative, so we won't get into details, but here is an outline of the analysis:
The span of P-MERGE is the maximum span of a parallel recursive call. Notice that although we divide the first list in half, it could turn out that x's insertion point q2 is at the beginning or end of the second list. Thus (informally), the maximum recursive span is 3n/4 (as at best we have "chopped off" 1/4 of the first list).
The text derives the recurrence shown below; it does not meet the Master Theorem, so an approach from a prior exercise is used to solve it:

Given 1/4 ≤ α ≤ 3/4 for the unknown dividing of the second array, the work recurrence turns out to be:

With some more work, PM1(n) = Θ(n) is derived. Thus the parallelism is Θ(n / lg2n)
Some adjustment to the MERGE-SORT' code is needed to use this P-MERGE; see the text. Further analysis shows that the work for the new sort, P-MERGE-SORT, is PMS1(n lg n) = Θ(n), and the span PMS∞(n) = Θ(lg3n). This gives parallelism of Θ(n / lg2n), which is much better than Θ(lg n) in terms of the potential use of additional processors as n grows.
The chapter ends with a comment on coarsening the parallelism by using an ordinary serial sort once the lists get small. One might consider whether P-MERGE-SORT is still a stable sort, and choose the serial sort to retain this property if it is desirable.